
关注“金科应用研院”,回复“礼包”领取风控资料合集
文末有惊喜小福利,记得看到底呦
- 在预期范围,偶尔几周出现变量分布交叉
- 上线模型监控PSI某一周突然上升,下一周又快速跌回预期范围
- 上线模型整体表现逐月缓慢衰退
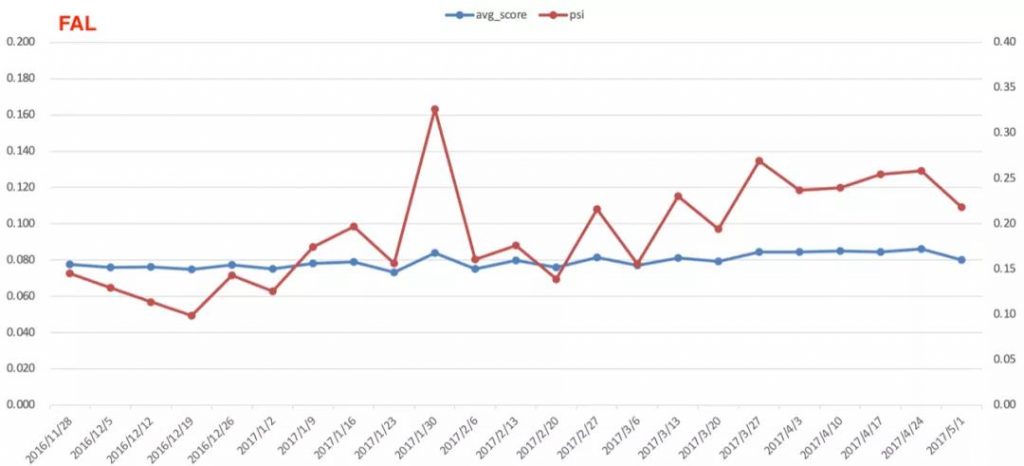
导致出现上述现象的原因有很多,比如,第5点可能是观察异常的几周内进件客群发生了变化,这类问题可以静观其变不需要调整模型。当然,有些现象的出现会导致模型上线后发生模型风险,需要模型开发人员立刻解决。
其中,回归系数符号与实际情况相反这种情况,就属于上述模型风险范畴。
一般,出现回归系数符号与实际情况相反是因为模型变量中存在共线性。
共线性指的是模型的变量之间存在较高的相关性,某一个变量可以被其他一部分变量所解释。
道理很简单:一个指标光是自己表现的足够好也是没有用的,还要考虑它和所有其他自变量之间的“团队协作能力”。一个优秀的团队,往往需要队员之间取长补短,各自分工,而不是大家擅长的事物都一样,而短板却无人弥补。
放在模型上也是一样的道理。如果模型中的自变量之间具有完全多重共线性,那么训练出来的系数便会失去统计学意义。即使是不完全共线性,也会导致系数失真,从而导致模型的效果无法达到预期。
通常,我们可以用VIF(方差膨胀系数)来检验模型共线性问题,完整Python代码如下:
import re
import os
import sys
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from termcolor import cprint
import lightgbm as lgb
from joblib import Parallel, delayed
import time
import toad
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.base import TransformerMixin, BaseEstimator, ClassifierMixin
from sklearn.metrics import roc_auc_score, roc_curve
class Metrics:
@classmethod
def get_auc(cls, ytrue, yprob, **kwargs):
auc = roc_auc_score(ytrue, yprob)
if kwargs.get('symmetry', False) is True:
if auc < 0.5:
auc = 1 - auc
return auc
@classmethod
def get_ks(cls, ytrue, yprob):
fpr, tpr, thr = roc_curve(ytrue, yprob)
ks = max(abs(tpr - fpr))
return ks
@classmethod
def get_gini(cls, ytrue, yprob, **kwargs):
auc = cls.get_auc(ytrue, yprob, **kwargs)
gini = 2 * auc - 1
return gini
@classmethod
def get_stat(cls, df_label, df_feature):
var = df_feature.name
df_data = pd.DataFrame({'val': df_feature, 'label': df_label})
# statistics of total count, total ratio, bad count, bad rate
df_stat = df_data.groupby('val').agg(total=('label', 'count'),
bad=('label', 'sum'),
bad_rate=('label', 'mean'))
df_stat['var'] = var
df_stat['good'] = df_stat['total'] - df_stat['bad']
df_stat['total_ratio'] = df_stat['total'] / df_stat['total'].sum()
df_stat['good_density'] = df_stat['good'] / df_stat['good'].sum()
df_stat['bad_density'] = df_stat['bad'] / df_stat['bad'].sum()
eps = np.finfo(np.float32).eps
df_stat.loc[:, 'iv'] = (df_stat['bad_density'] - df_stat['good_density']) * \
np.log((df_stat['bad_density'] + eps) / (df_stat['good_density'] + eps))
cols = ['var', 'total', 'total_ratio', 'bad', 'bad_rate', 'iv', 'val']
df_stat = df_stat.reset_index()[cols].set_index('var')
return df_stat
@classmethod
def get_iv(cls, df_label, df_feature):
df_stat = cls.get_stat(df_label, df_feature)
return df_stat['iv'].sum()
class Logit(BaseEstimator, ClassifierMixin):
def __init__(self):
self.model = None
self.detail = None
def fit(self, df_xtrain, df_ytrain, **kwargs):
df_xtrain_const = sm.add_constant(df_xtrain)
# model training. default using newton method, if fail use bfgs method
try:
self.model = sm.Logit(df_ytrain, df_xtrain_const).fit(method='newton', maxiter=100)
except:
cprint("warning: exist strong correlated features, "
"got singular matrix in linear model, retry bfgs method instead.",
'red')
self.model = sm.Logit(df_ytrain, df_xtrain_const).fit(method='bfgs', maxiter=100)
# prepare model result
self.detail = pd.DataFrame({'var': df_xtrain_const.columns.tolist(),
'coef': self.model.params,
'std_err': [round(v, 3) for v in self.model.bse],
'z': [round(v, 3) for v in self.model.tvalues],
'pvalue': [round(v, 3) for v in self.model.pvalues]})
self.detail['std_data'] = df_xtrain.std()
self.detail['feature_importance'] = abs(self.detail['coef']) * self.detail['std_data']
return self
def predict(self, df_xtest, **kwargs):
return self.model.predict(sm.add_constant(df_xtest))
def predict_proba(self, df_xtest, **kwargs):
yprob = self.model.predict(sm.add_constant(df_xtest))
res = np.zeros((len(df_xtest), 2))
res[:, 1] = yprob
res[:, 0] = 1 - yprob
return res
def summary(self):
print(self.detail)
def get_importance(self):
return self.detail.drop('const', axis=0)
class VIFSelector(TransformerMixin):
def __init__(self):
self.detail = None
self.selected_features = list()
def fit(self, df_xtrain, df_ytrain, **kwargs):
vif_threshold = kwargs.get('vif_threshold', 10)
n_jobs = kwargs.get('n_jobs', -1)
feature_list = sorted(kwargs.get('feature_list', df_xtrain.columns.tolist()))
# compute VIF
vif = Parallel(n_jobs=n_jobs)(
delayed(variance_inflation_factor)(df_xtrain.values, i) for i in range(df_xtrain[feature_list].shape[1]))
# select features with VIF < vif_threshold
df_res = pd.DataFrame({'var': feature_list,
'vif': [round(v, 3) for v in vif]})
df_res.loc[:, 'selected'] = df_res['vif'] < vif_threshold
self.detail = df_res
self.selected_features = df_res.loc[(df_res['selected'] == True), 'var'].tolist()
return self
def transform(self, df_xtest, **kwargs):
feature_list = kwargs.get('feature_list', df_xtest.columns.tolist())
feature_list = sorted(set(feature_list) & set(self.selected_features))
return df_xtest[feature_list]
def summary(self):
print('selected features:')
print(self.selected_features)
print('summary')
print(self.detail)
model_vif = VIFSelector()
model_vif.fit(df_xtrain, df_ytrain)
print(model_vif.detail)VIF阈值选取标准相对主观性。通常,如果VIF的阈值小于10(严格是3),则说明模型没有多重共线性问题,模型构建良好;反之若VIF大于10说明模型构建较差。
当选出VIF>3的变量特征后,有什么方法可以移除共线性变量呢?
这里提供一个方法:综合考虑单变量或多变量的AR值。
举个例子,如果变量A同时和变量B、变量C存在较强相关性,而变量B和变量C相关性较低,那么究竟应该保留A还是同时保留B和C呢?
有一个比较简单的思路,可以计算变量A的单变量AR值,同时用变量B和变量C训练一个简易的逻辑回归模型,并计算这个模型的AR值,通过比较变量A和模型的AR值来判断到底应该保留A还是B+C。
如果变量A的AR值比模型的AR值还高,就说明变量A的表现会优于B和C的综合表现,这时,就可以剔除掉B和C了。
如果你喜欢、想要看更多的干货类型的文章,可以关注公众号【金科应用研院】并设为星标,顺便转发分享~
感谢您看到这里微信公众号【金科应用研院】对话框回复“小福利”,领取粉丝专属优惠券。
