
在评分卡模型的模型评估中,除了计算基本的技术指标之外,检查信用分的实际分布是个关键性的步骤。
比如分数分段,看总体分布,逾期分布,分数对比这些。我总结了下这些分析的常规代码,供参考。
首先我们把数据排列成如下的结构,方便后续的分析:

分数分段uid是用户编号,month是月份,可以拓展成任何其他需要分析的维度,score是我们关注的信用分,label是好坏用户标签,True表示用户有逾期,是坏客户,False表示用户无逾期,是好客户。
分数分段的方法
分析分数第一步是把分数进行分段,一般常用三种切分方式:
- 等频分段
- 等距分段
- 给定切分点分段
我们使用一个python包和toad完成上述功能:
(https://toad.readthedocs.io/en/latest/),可以使用pip install toad来安装这个。
1、等频分段

使用上面的代码对pandas的dataframe来操作。需要明确两个列:score和label,然后method设置成quantile表示等频分段,n_bins=10表示分十段,计算好使用transform来保存分段的结果,记录在dataframe的bin列中。
切分出的结果如下:
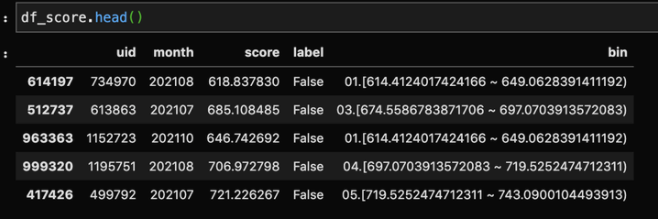
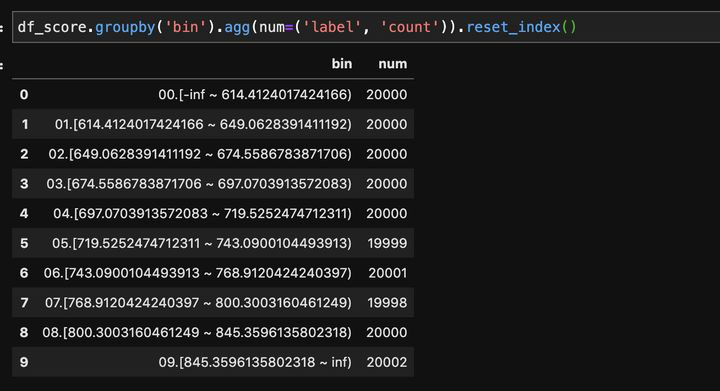
既然是等频分段,我们把每一段的人数一数,看看是否相等:

可以看出每段人数基本上是差不多的。
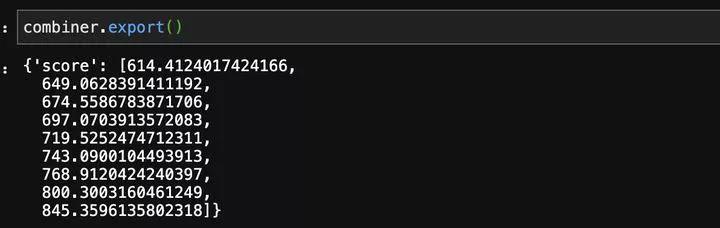
如果需要把这个分段信息应用在其他地方,我们可以使用export()方法把分段的切分点信息导出,然后使用后面介绍的按给定切分点分段方法进行分段。
2、等距分段

代码其实和等频分段基本一样,只是把method改为step,就变成等距分段了。
切分出的结果如下:
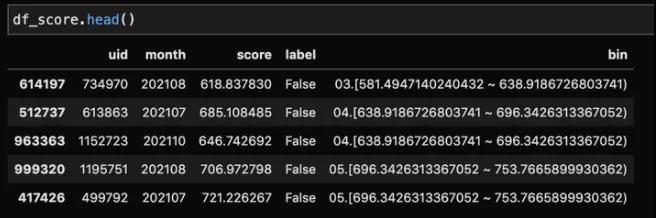
可以看下每个分数段的人数,很明显在等距的情况下,不同分数段的人数是有比较大的差异的。
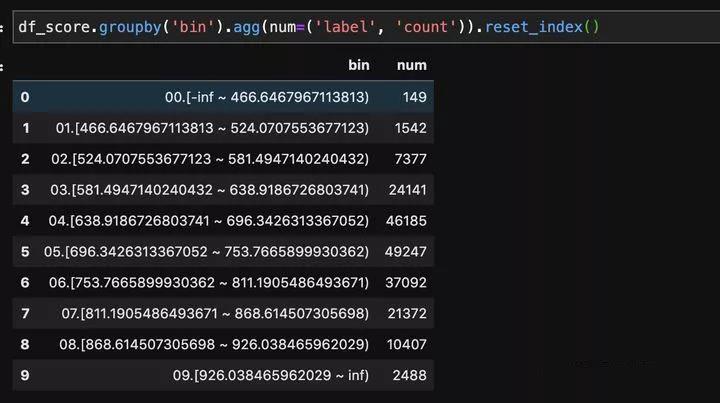
3、按给定切分点分段

我们使用toad里combiner的update方法把combiner内置的切分点信息修改成我们需要的数值。
比如我们要把score列按照[300, 350, …, 800, 850]来切分,那我们就是把combiner里的记录切分点的字典改成{‘score’: [300, 350, …, 800, 850]}就好了,然后update方法就是帮我们做这件事情。
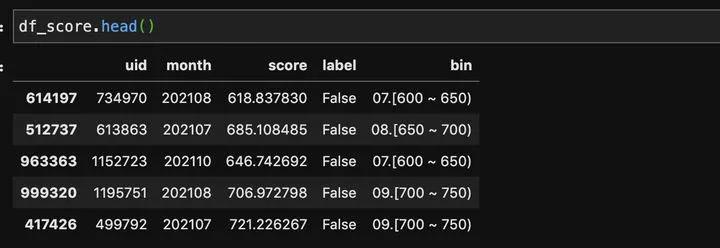
分段后的数据如下,可以看出按指定分数段切的bin比较的规整,不会那么多小数点看着闹腾。
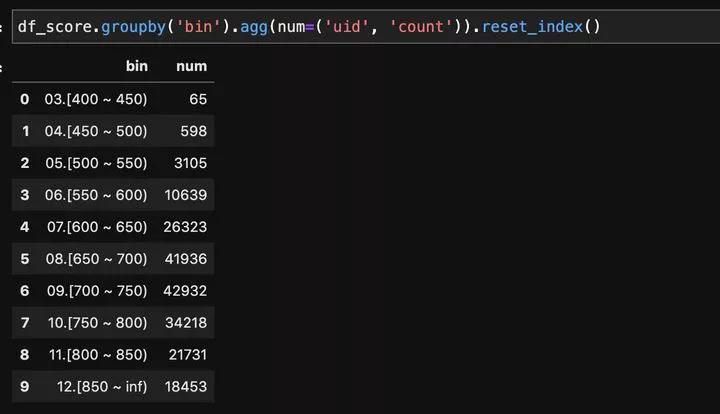
我们同样用groupby看下各个分数段上的人数分布:
分数段指标统计
1、分数段人数统计
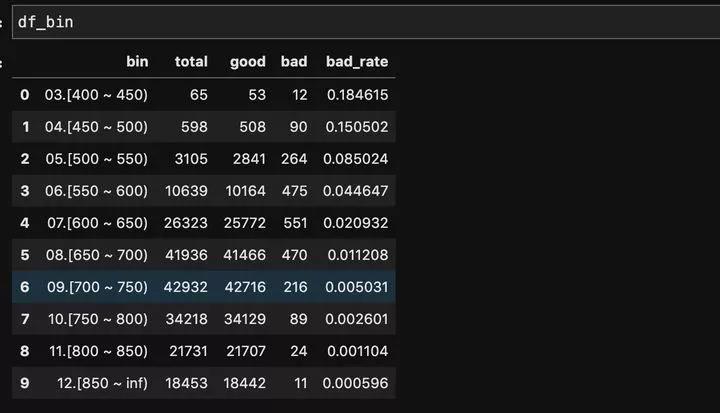
其实groupby用好可以简化很多操作,像计算各个分数段上的用户总量,好坏用户个数和逾期率都可以一个groupby搞定,见下面的代码:

计算出的总人数,好人个数,坏人个数和逾期率如下:
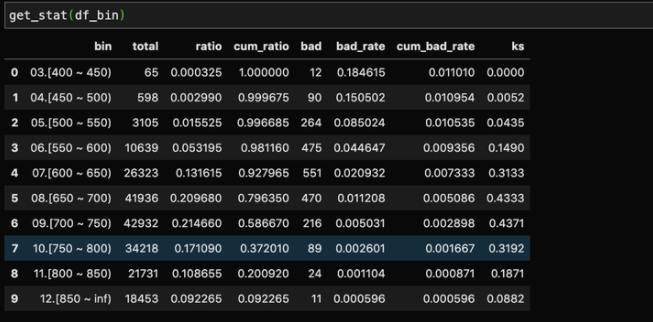
如果要更详细的统计指标,像累计人数,累计分布和分数段上的KS数值,可以用下面的一段代码获得:

展示的数据结果如下:
2、逐月分数段统计
上面我们看来不同分数段的总体情况,我们很多时候想看分维度的分数分布,尤其是各个月份的变化趋势。
这时候我们就要在上面的groupby的语句里增加一个month的维度来做聚合,聚合完了再用pivot把month的维度从行转成列,就能把逐月的分布计算出来,其他的维度做法和month类似。

我们从上面的代码能拿到四个重要的dataframe:
- 逐月的总用户数的分布 df_total
- 逐月坏用户数的分布 df_bad
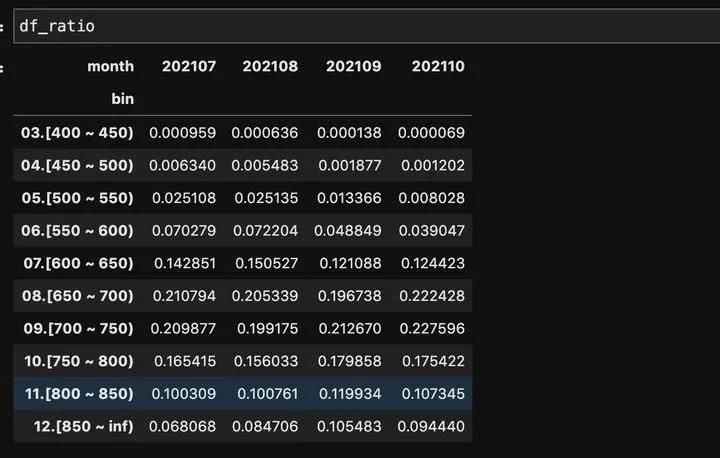
- 逐月总用户人数比例 df_ratio
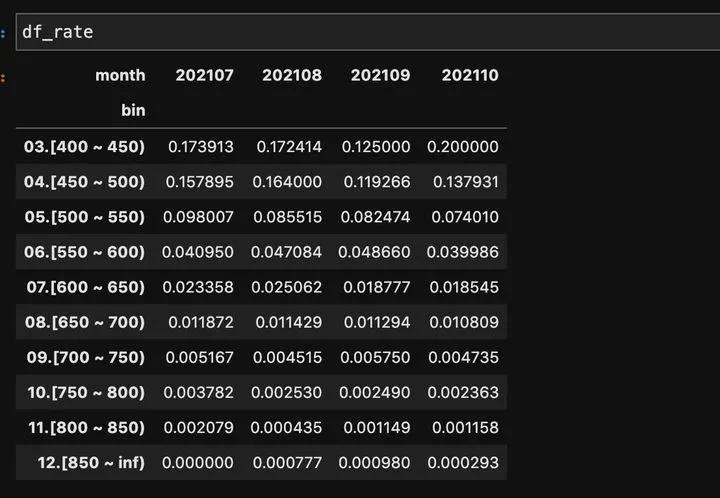
- 逐月逾期率分布 df_rate
我们看下总用户的比例:
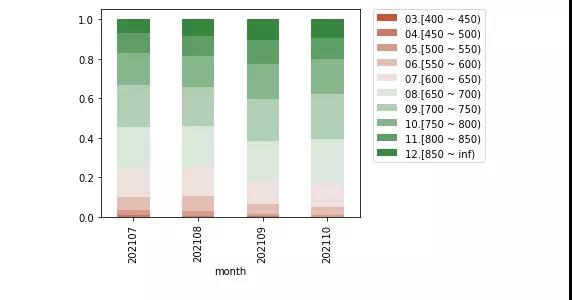
可以用下面的画图语句把逐月的人数比例画成堆积图:

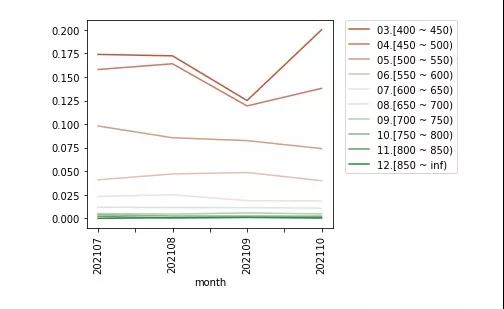
逐月的逾期率数据df_rate如下:
同样给出画图的代码:

3、两个分数交叉比较
我们除了分析单个分数的性能之外,还会把两个分数做比较。一个比较重要的做法就是做矩阵交叉。
为了演示,我们随机生成一个信用分,并按20分一段做分数段的统计。

然后把我们原来的信用分和随机生成的信用分做分数交叉。这里使用到一个pandas自带的函数pd.crosstab来生成交叉矩阵。
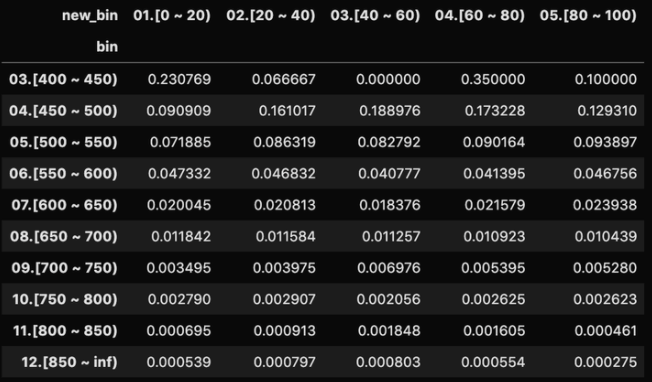
上面这个矩阵要怎么解读呢?
我们首先按行来看,每一行里的逾期率在随机分的分数段(每一列)中逾期率是没有顺序的,说明随机信用分在原有信用分上没有额外的区分度。
然后我们按列来看,每一列的逾期率从上到下是从大到小有序排列的,说明在随机分的基础上,原有信用分有额外的区分度,这就说明原有信用分对好坏用户的区分度好于随机分。
当然,这在我们这个例子下是显而易见的,但如果是两版真实模型生成的信用分,这样的顺序性是没有这么明显的。
总结
我们总结了分数分段的方法和在分数段中的几个统计量的常用代码,包括:
- 分数分段方法:等频,等距,给定切分点
- 统计量的代码计算:基本统计,逐月统计,分数交叉
如果你喜欢、想要看更多的干货类型的文章,可以关注公众号【数据科学应用研院】并设为星标,顺便转发分享~
感谢您看到这里微信公众号【数据科学应用研院】对话框回复“礼包”,领取粉丝专属干货资料包。
