
自然语言主要指人们交流用的正式或非正式语言,自然语言处理(NLP)则是将人类语言转换成计算机能理解的符号或将机器语言转换成人可以理解的语言。
自然语言处理是人工智能领域的一个重要研究方向,是计算机科学与语言学的交叉学科。
自然语言处理有2大核心任务,自然语言理解(NLU)和自然语言生成(NLG)。对人来说,理解语言是一件很自然的事情,但对机器来说却是很困难的事情。所有语言的鲁棒性都是导致自然语言理解的主要难点,其中包括:语言的多样性、歧义性、知识依赖、上下文关系等。
2001-2021,一文读懂NLP发展简史自然语言生成是将机器理解到的信息,一般是非文字的数据内容,转化并表达成语言传递给人的过程。这个过程面临的困难则是生成语句的语法结构、语义表达是否准确,信息是否重复等。
为了解决上述问题,一些基本的自然语言处理方向便应运而生,包括:分词、词性标注、词形还原、依赖关系解析、命名实体识别、序列标注、句子关系识别等。
除此之外,自然语言处理还包括了很多具体应用,例如:信息检索、信息抽取、文本分类与聚类、机器翻译、摘要生成、聊天机器人等等。它涉及与语言处理相关的数据挖掘、机器学习、语言学研究,以及近年来非常流行的深度学习等。
以前人们通常通过经验主义,即特征工程的方式,或统计信息的方式来解决NLP问题,文本的表征也只是简单的词袋表示(Bag-of-Words, see Figure 1),这种方式使得文本丢失了序列信息以及背景依赖信息等。
从2001年的嵌入式词向量表示到2013年的word2vec (see Figure 2),研究已经逐步解决传统词袋表征方式的无序性,并进一步丰富了表征向量的表达能力。
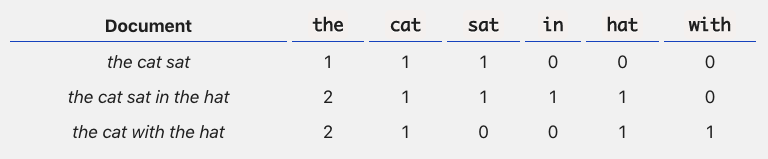
Figure 1: Bag-of-Words Example
Figure 2: 嵌入式词向量表示 (word embedding)
2013到2014年,各种神经网络模型在NLP上的应用逐渐增多,其中应用最广泛的是:卷积神经网络(convolutional neural networks, CNN)、循环神经网络(recurrent neural networks,RNN)和结构递归神经网络(recursive neural networks)。
因为文本是有序的,而RNN (see Figure 3)的序列性结构使其成为了最贴合文本输入的网络模型,也是大量研究工作的首选基础框架。为了解决RNN模型梯度消失和爆炸的问题,经典的长短期记忆网络(long-short term memory networks,LSTM)以及其改进版本门控循环单元(gated recurrent unit, GRU)开始被广泛应用。

Figure 3: Recurrent neural network, RNN
2014 年Sutskever 等人提出了序列到序列学习(sequence-to-sequence see Figure 4),即是用神经网络将一个序列映射到另一个序列的框架模式。编码器将输入文本转换为表示向量,解码器将向量转化为输出文本序列。
这个结构一经提出便迅速被应用到机器翻译,并逐步取代了基于短语的整句机器翻译模型。
但编码器需要将输入序列整合成固定大小的向量,使得很多输入信息被忽略甚至丢失,导致解码效果不佳,因此注意力机制被提出(attention model)。
注意力机制使得解码器有针对性的对编码序列进行解读,在输入序列上引入注意权重,以优先考虑存在相关信息的输入位置信息,以生成下一个输出。注意力机制被广泛应用到机器翻译、阅读理解等任务。
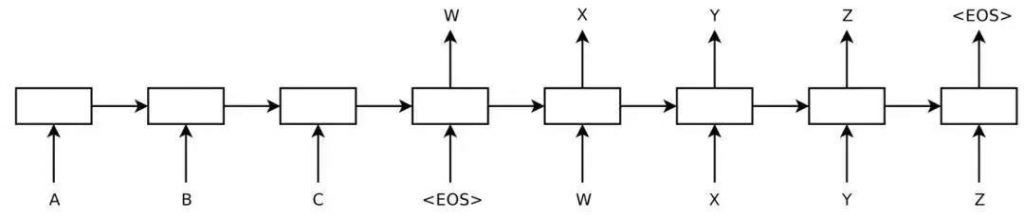
Figure 4: Sequence-to-sequence model
受图像学习的影响,预训练语言模型在2015 年被首次提出,但在2018年才发生了重大进展,以Google提出的BERT (see Figure 5)为代表的预训练语言模型,被证实在大量NLP任务上都很有效,例如ELMO,XLNet,GPT,RoBERTa, ALBERT等。
这些预训练语言模型均是无监督形式,使得模型能够从无标注语料中获得通用的语言建模能力。而后模型可以根据少量的标注数据进行任务导向的微调,使得模型不需要大量的训练数据也能够达到不错的效果,可很大程度缓解低资源任务对大量标注数据的需求。
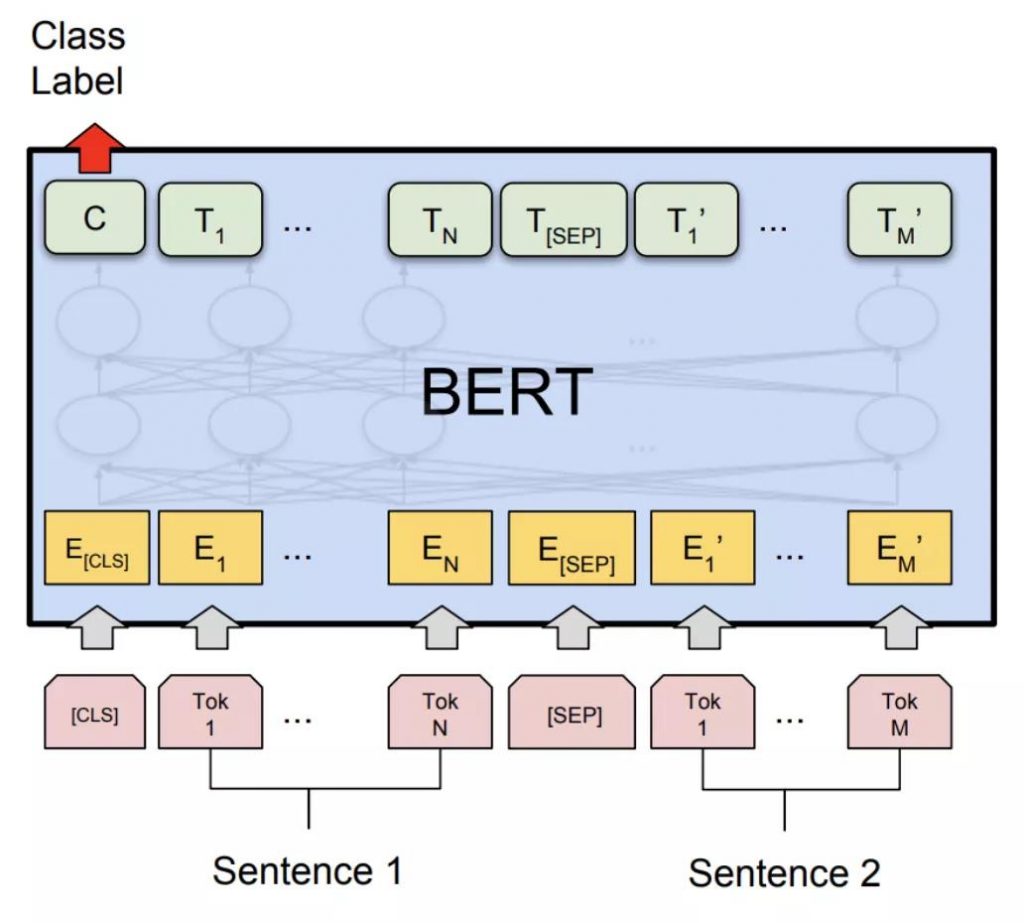
Figure 5: BERT
虽然近年来NLP领域迅速的发展,但很多任务的表现还远达不到人们的期望,其研究仍 任重而道远。
更多数据科学干货,关注公号【数据科学应用研院】,回复【官网】,还能获得数据科学大礼包一份哦!
