
在大数据和人工智能异常火爆的当下,数据科学家已成为一个炙手可热的岗位,如何成功从众多码农/取数机器人标签中脱颖而出,站上鄙视链顶端,成为一名数据科学家。本篇将会从三个角度全面剖析,目录如下:
目录
1.真实的数据科学相关工作
2.一名合格的数据科学家画像
3.案例详解数据科学家的常规工作流程
3.1沟通需求
3.2整理数据
3.3特征工程
3.4模型训练
3.5模型报告
在真正开始前,我有必要给广大读者朋友们做一个小科普:数据科学家(Data Scientist)是源于国外,其工作流程以及内容与国内的建模工程师、算法工程师甚至大数据分析师类似。大家不要被“科学家”三个字所吓到。
1、数据科学工作:你以为 VS 实际上
在很多人眼里,数据科学家的工作似乎光鲜亮丽,充满技术含量:

但实际上,数据码农的工作状态通常是这样的:

数据科学家的一天可能是这样开始的:
早上到公司,先打开邮箱查看需求方的新需求和负反馈。然后打开jupyterlab开始进行数据校对,把问题反馈给工程开发的小伙伴。或者写文档,插入一些分析示意图,以帮助需求方可以通过图表更好地理解数据。
与此同时,将还没开始Run的报表和实验启动下,甚至耍耍小心机将当天要用的spark资源先占住,毕竟数据工作者处理的数据不管是结构化还是非结构化,都会是庞大的。
不出意料,之前的报表和实验结果,90%的情况下效果不甚理想。正要找原因的时候,会议提醒闹铃响了,马不停蹄赶到会议室,给业务需求方对接交代需求进展和预期效果。
下午时间抓紧做报表和实验,将上午跑的实验结果仔细校对,如果发现一堆数据问题,则开始挨个检查样本数据,重新计算成特征,再重新跑实验……经过九九八十一次调整后,实验效果才能显现出来。此时抬头一看,已经是晚上九点半了。
虽然这是一个举例,但不难看出数据科学家的日常就是围绕需求与数据,不断做实验与模型。
2、合格的数据科学家画像
上述才是数据科学家的真实日常。其实数据科学家的工作不仅仅是处理数据,制作模型,还涉及大量的沟通协调,和上游的数据源端沟通数据逻辑,和下游的业务方沟通需求和数据服务效果等。优秀的数据科学家,一般都兼具过硬的技术能力和一流的沟通水平。
①技术部分:
- 调研所需数据源
- 分析原始数据
- 校验数据质量和逻辑
- 特征工程
- 特征评估
- 模型训练
- 模型部署
- 线上模型运营
- 书写特征和模型文档
②沟通部分:
- 和上游数据端沟通数据逻辑
- 提供数据问题的案例并跟进上游数据问题的解决进度
- 收集下游业务方的需求
- 和下游业务方探讨项目的预期效果和排期
- 向业务方汇报数据服务的实验结果和预期效果
- 收集业务方使用数据服务的反馈意见并有针对性的改进
把这些点串成一个项目流程的话就是如下的步骤:
- 对接需求
- 数据调研
- 数据治理
- 特征工程
- 模型构建
- 模型运营
3、案例详解数据科学家的常规工作流程
本文以信贷风控建模项目为例,让我们具体来看看数据科学家的工作流程。
3.1.沟通需求
信贷风控要评估用户的信用风险,即需获取用户个人数据,以此为依据给用户信用评分。在开展项目前,最开始需要了解需求方的需求:目前公司开展线上小额信贷业务,需要一个贷前风控信用评分模型,以便能精准且客观的区分好坏等级客群。
3.2.整理数据
顺利完成需求沟通后,数据科学家需要在公司数据库里找到与项目相关的数据,并与数据源的负责人沟通,了解数据收集和存储情况,确定是否适合在风控项目中使用。
例如某数据表里的性别字段不是用户填写的,而是我司根据用户行为数据预测出来的,那这个数据就不太适合直接使用在信贷风控模型里。
因为模型使用的数据一般都是一手数据,经过其他模型加工预测出的数据,其自身稳定性会随着模型版本的变化而变化。如果一定要用这个性别数据,更建议直接把预测这个性别用的原始数据放到信贷风控模型的输入中。
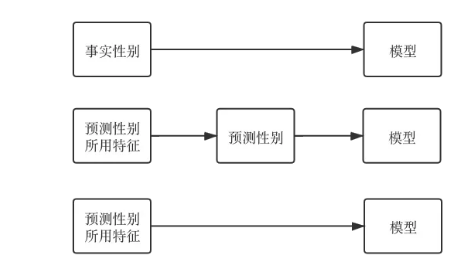
确定数据后,接下来就是检查数据质量。一通SQL查询操作,把数据整理到pandas里。这里福利给到我们的读者朋友们,贴上常见的spark查询转pandas的代码模板:
sql_stmt = “””
SELECT a, b, c, … FROM table WHERE XXX
“””
spark_df = spark.sql(sql_stmt)
median = F.udf(lambda x: float(np.median(x)), FloatType())
cnt_case = lambda c: F.sum(func.when(c, 1).otherwise(0))
avg_case = lambda c: F.mean(F.when(c, 1).otherwise(0))
lst_expr = [
F.count(‘a’).alias(‘ft_a’),
F.countDistinct(‘b’).alias(‘ft_b’),
F.sum(‘c’).alias(‘ft_c’),
func.mean(‘d’).alias(‘ft_d’),
median(F.collect_list(F.col(‘e’))).alias(‘ft_e’),
func.max(‘f’).alias(‘ft_f’),
cnt_case(F.col(‘g’) > 0).alias(‘ft_g’),
cnt_case(F.col(‘h’).isNotNull()).alias(f’ft_h’),
avg_case(F.col(‘i’) > 0).alias(‘ft_i’),
cnt_case(F.col(‘j’) != -1).alias(f’ft_j’)
]
spark_feature = spark_df.groupBy(‘pkey’).agg(*lst_expr)
pandas_feature = spark_feature.toPandas()
结果运行完查询语句一看,收入栏中80%的数据缺失,地址栏全是手填乱码和拼写错误等等一堆数据问题。这些都是数据质量不佳引起的。
常见的数据质量问题包括:
- 数据覆盖度过低 (20%~30%)
- 数据里零值率过大 (特征很多都是数数,零通常表示没有数据)
- 数据稳定性差 (按时间看数据分布差异过大)
- 数据逻辑错配 (本来存A数据的存成B了)
作为一名合格的数据科学家,一定要有足够的耐心,把出现问题的对应数据都记录下来,然后和数据源的负责人沟通。基本上绝大数数据问题在多次沟通中都能找到解决办法。(其实这里还有一个经验操作:大多数情况下,把出问题的数据丢弃不用就是最佳解决方案,不然等上游解决数据问题的话,项目就延期到明年了)。
3.3.特征工程
刚解决完数据问题,下一步就要开始做特征工程。对于大多数数据科学家,常常看到整理完数据后的十来张表的数据,这心情,怎一个愁字了得。
但对一个有经验的数据科学家来说,少数据也能大跃进,各种排列组合大法做特征,用户维度、关系网络、时间截面、时间序列、embedding都可以尝试一遍。
这里,我们举一个例子详细介绍下怎么让数据“四象升八卦”:假设我们现在有用户的购物订单数据,
从单个用户角度:可以计算用户订单数,订单GMV等。
从关系网络角度:计算一个用户收货地址所在省市区的平均订单数/GMV,下单所在时间段平均订单数/GMV,下单所在IP段平均订单数/GMV
时间截面:最近大促期间的订单数/GMV
时间序列:最近1/3/6/12个月的平均订单数/GMV
Embedding:拿用户订单所买商品构造item2vec
通过上面列举的一些特征处理方法,可以看到将单一订单数据源,能衍生出好几百个特征。
需要提醒的是,构造完这些特征后,需要拿用户case核对下数据。如果特征计算结果都和实际用户数据能匹配上就可以开始做特征评估。
3.4.模型训练
将做好的特征和样本标签利用机器学习、深度学习算法如逻辑回归、随机森林和XGBoost等进行训练。不出意外,刚开始的表现都不会很理想,这时一般不要急着在模型上找问题,经验上判断,十有八九还是数据上有缺陷,最常见的问题就是特征不稳定。
因为模型是在训练集上拟合的,在测试集上效果不好的最直接原因就是训练集上的特征分布和测试集的不一样。这时候再去看看各个特征维度上的空值率和零值率基本就能把不稳定的特征找出来。
举个例子,我们发现上面构造的订单数特征不稳定,那怎么把这个特征做稳定呢。
通常不稳定都是统计的数据时间跨度太短,数据总数过少造成的,像订单数很受短期大促影响,我们就可以把统计的时间跨度拉大,把本来一周的统计跨度变成3个月,把算最大单数的逻辑改成算平均单数,这样特征就会相对稳定了。
如果还是不稳定,那还有最后一个办法,把这个特征遗弃。把遗留的数据问题都排查干净。接下来就是比较玄学的环节:特征选择+参数调优。
为什么说玄学,是因为通常很难在短时间内理清楚为什么特征动一动,参数调一调,效果就变好了,对于有经验的数据科学家,常常模型调优是很快的,这就是大家常听到的“数据敏感性”。
能回答为什么会变好是个大海捞针的过程,在缺少思路的时候,多与业务同事讨论下变动特征的业务逻辑,一般能够比较容易帮助找到相关的线索。
3.5.模型报告
信贷风控模型开发完后,还需要一个详尽的模型报告。
模型本身可以较简单,但模型报告需要很详细的呈现模型的每个核心环节和结果。
比如,把每个人群的信用风险的特点描述一遍,对比新老模型性能,分数交叉矩阵,估计分数波动范围。这些与业务紧密联系的分析型工作都要在模型报告里按照业务方逻辑很充分的呈现出来。小白新手才会直接告诉需求方模型二分类技术指标AUC达到0.8。
在需求方评估完模型后,就要尽快模型上线。
一般有经验的数据科学家,都会在做完模型初稿后,就跟负责上线的同事沟通,在暂时不care模型效果的前提下,让相关同事帮忙先把上线流程跑通,确保没有技术问题,等到需求方批准模型后立马上线。
当然,模型上线后项目并未结束,需要认真地跟需求方介绍模型如何应用,避免因为使用逻辑不对造成大家对模型效果的误判。以及上线模型的监控管理运营工作。
至此,一个数据模型项目就算全部结束了。大家应该可以感受到,数据科学家在工作内容上还是有一些比较特殊性的,不仅仅要懂python编程和数据分析建模,更重要的是要有对业务的理解,并且需要较高的沟通交流能力,能用技术语言和上游沟通,用业务语言和业务沟通。
希望所有从事数据科学的读者朋友们,看到此文有所收获。
FAL宠粉活动来啦!现在扫码助力即可领取数据科学书籍、python快速入门课程、图像算法课程!限量前500名用户!
↓↓↓扫码关注,回复【领书】↓↓↓
