
实时模型指的是需要在线上实时获取数据并输出结果的模型。常用于一些实时申请业务,例如欺诈模型和征信模型。
常见问题:是使用实时模型还是离线模型?
解释这个问题,可以从下面2个角度分析。
首先,从业务角度来看,首先需要确认是否需要实时审批,如果不需要,那就可以直接用离线模型。
其次,从数据角度看,可以用以下2个方面来判断:
- 是否有需要实时调用收费的数据源
- 是否需要使用当天的实时申请数据
如果有这两个方面数据要求,那就需要实时模型。
例如,在风控模型中,有些风控模型需要用到用户填写提交的实时申请表数据,这时就要实时模型。但如果在电商环境下的风控模型,从电商交易行为入手,模型性能已经很强了,完全不需要外部数据或者申请表数据,那就可以用离线模型,给所有用户先打好分。
实时模型的开发,可以分为以下3个步骤:
- 模型训练:利用离线数据对模型进行训练
- 线上部署:把训练好的模型放到实时数据流中进行测试
- 实时调用与模型监控:测试完毕后,正式开始使用并对模型输入和输出进行监控
接下来我会对这3个步骤分次进行详细解释。
模型训练
实时模型的训练和离线模型的训练基本一样,都是用到历史数据和样本进行训练。唯一需要注意的点是,离线原始数据存储格式可能和线上数据不一致。这里最好保持原始数据格式一致,不然线上和线下两套变量逻辑非常容易出错。
举个例子,线上数据流一般是json格式。但离线存储的时候,为了方便分析,很多团队会把json的数据解析后进行存储。如果在抽取离线训练变量的时候使用这种解析后的数据,就会造成和线上数据流的格式不一致。
这里推荐在数据存储的过程中,一定要先存一份完整的json数据。而取训练数据的时候也用这些json数据。如果这些json数据是打包存在Spark的一个列下的,则推荐使用PySpark的Pandas UDF函数去json里面抽取变量。
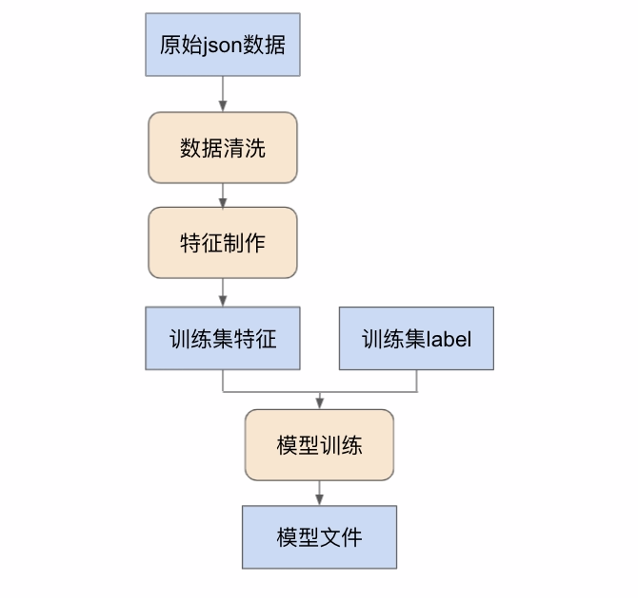
图1:模型训练流程
如上图所示,在训练模型的时候,建议从原始数据库里面直接拿原始数据。然后,对数据进行清理和处理,变成训练模型使用的特征。这里要注意的是,数据清洗和特征制作逻辑需要和上线后保持一致。所以,这里建议代码就写一套,线下用这套代码,线上也用这套,保证不会在这一步出错。
模型训练这一步在网上有很多教程,包括了模型选取,调参等。这些大家可以在FAL其他历史文章中学到,也可以在FAL的风控模型训练营里学习,这里就不多赘述。

训练好模型后,把模型文件保存下来。模型文件格式没有限制,可以是模型python包自带的存储方式,也可以存成Pickle格式,只要方便读取就好。
保存好数据清洗,特征制作代码和模型文件后,我们就可以开始第2步,线上部署和调试。线上部署和调试,我们在下一篇为大家分享。
推荐参加我们的风控模型训练营,我们在第二周直播实操训练LGBM和模型监控中,会详细介绍实时模型全流程的训练,线上部署和模型监控,第6期量化风控模型训练营本月即将开课,期待与大家课上交流。

One Reply to “实时模型全流程-训练,线上部署和监控”
Comments are closed.