
之前有详细说明实时模型的训练流程,传送门:实时模型全流程-训练,线上部署和监控
概要:
实时模型的开发,可以分为以下3个步骤:
- 模型训练:利用离线数据对模型进行训练
- 线上部署:把训练好的模型放到实时数据流中进行测试
- 实时调用与模型监控:测试完毕后,正式开始使用并对模型输入和输出进行监控
本文我为大家讲解如何利用数据清洗,特征提取制作的代码和训练好的模型文件进行线上的部署和测试。
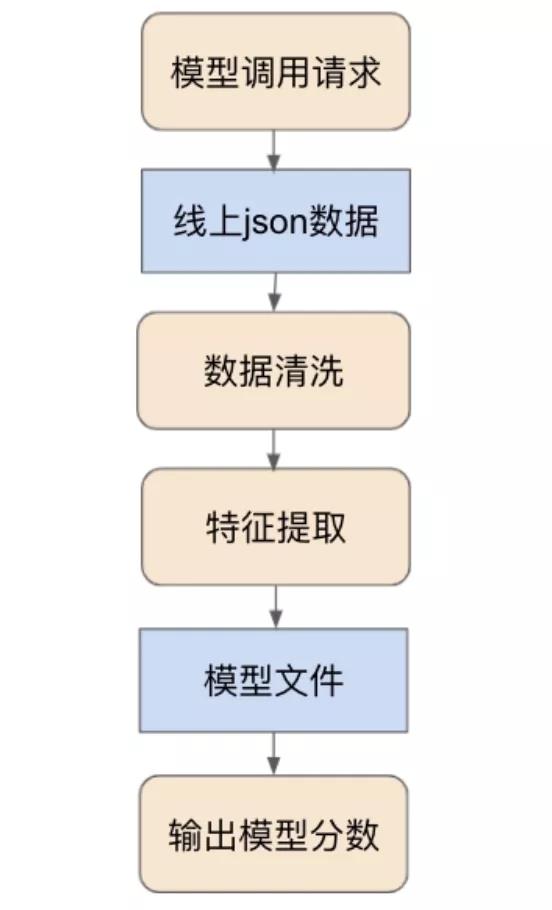
图2:实时模型线上数据流
可以看到,线上数据流可以分为3步:
- 请求调用模型并输入原始json数据
- 清洗原始json数据和特征提取
- 预测分数并输出
1.模型调用请求
实时模型我们一般使用python flask的方式写一个API,让开发人员来call我们的模型。在call模型的时候需要注意的是一定要设置一个模型版本号,让开发人员把版本号写清楚,防止call错模型!如果模型版本号有问题,可以直接结束整个流程,返回一个版本错误信息。
2.数据清洗和特征提取
通过模型版本号和其他限制检查后,就需要对输入的原始json数据进行清洗并提取特征。
这里有2个需要注意的点。
- 线上数据清洗和特征提取流程尽量和模型训练时使用一套代码,这样才能保持逻辑一致。
- 数据清洗时还需要检查输入的json原始数据是否完整。
例如,本次call模型时输入的json数据缺少了某个重要的特征,这时我们需要直接结束整个流程,返回一个数据错误信息。
3.模型分数预测和结果输出
提取完特征后,就可以预测分数。这里需要注意的是,线上预测需要保证预测效率,所以可能需要优化整个模型预测。
线上数据流已经调通后,一般还需要做2个测试:
- 线上预测与离线预测的一致性测试,一般要求线上线下100%一致
- 线上效率测试,一般要求1条数据需要在200-500ms内返回
如果模型有不达标的地方则需要重新优化。
这里,就有往期模型训练营的A同学提出过一个问题:

课上老师答疑部分选取:
模型文件生成有问题,需要用同一批用户打分。看看做pmml前后给一个人打的分是否完全一致,理论上小数点后10位都一模一样才可以。
出现上述你的问题,可以先从以下这些方面去排查:
- 机器的精度不一样
- 在gpu上训练在cpu上跑测试
- Python包的版本不一致
- 特征有存储后读出的逻辑使得精度改变
4.实时模型的监控
实时模型正式上线后,需要有一个监控系统去检查模型,让我们发现线上数据bug,并且知道什么时候去更新模型。实时模型的监控和离线模型类似,可以分为数据特征监控,模型状态和输出分数监控。
- 数据特征监控:线上数据是非常容易出错的,实时模型的每一类数据都需要在调用模型前被监控。如果有数据异常状况出现,可以马上定位到特定数据库。
- 模型状态监控:在第三节的时候,可以看到整个数据流中是会出现很多错误报告的。每一步都是一个不同的错误报告,我们需要把这些错误报告的数量都记下来,检查究竟是什么错误。
- 模型分数监控:最后,模型分数的分布也需要被监控。模型的分数是极为关键的,需要经常查看。推荐设定预警系统。
具体的模型监控系统和代码实现,因文章排版字数限制,我们会在最新一期风控模型训练营中详细为大家讲解和实践。
Model_performance_report_table
最后,模型监控系统的开发是可以和线上部署同时开发的,这里推荐由不同的同事负责这两件事,最后能一起在线上使用。
